
Rohstoffe zuverlässig dosieren, Produktionsprozesse millisekundengenau steuern, vorbeugende Wartung, aber auch Qualitätssicherung on the fly – dies alles sind Anwendungen, bei denen IoT-Technologie ihre Stärken erweisen kann. Doch die neuen Technologien, etwa Streaming-Engines wie Kafka oder neuartige No-SQL-Datenbanken wie Mongo und Stores für Bilder, Akustik oder Filme lassen sich oft schlecht mit der scheinbar überkommenen SQL-Technologie integrieren.
Um Streaming-Module oder -Funktionen erweiterte klassische SQL-Applikationen oder dafür Gesamtlösungen dagegen haben andere Probleme. Sie sind komplex und beruhen oft auf proprietärer Hardware. Die Marktführer bei datenverarbeitenden Industrien für Unternehmen, zum Beispiel SAP mit HANA oder Oracle mit den modernen Varianten seiner Datenbank, kämpfen mit dieser Herausforderung, werden aber wohl bis auf Weiteres teuer bleiben.
„Die herkömmlichen Technologien sind ganz schlicht zu teuer für die Anwendungen, die sich jetzt abzeichnen“, sagt Christian Lutz, Mitgründer und CEO von Crate.io. Einer der Crate Kunden, der seine weltweit 180 Fabriken komplett digitalisiert, produziert schon heute 50 bis 100 Millionen Sensordaten-Records pro Tag, dabei seien erst zehn Prozent der Fabriken angeschlossen.
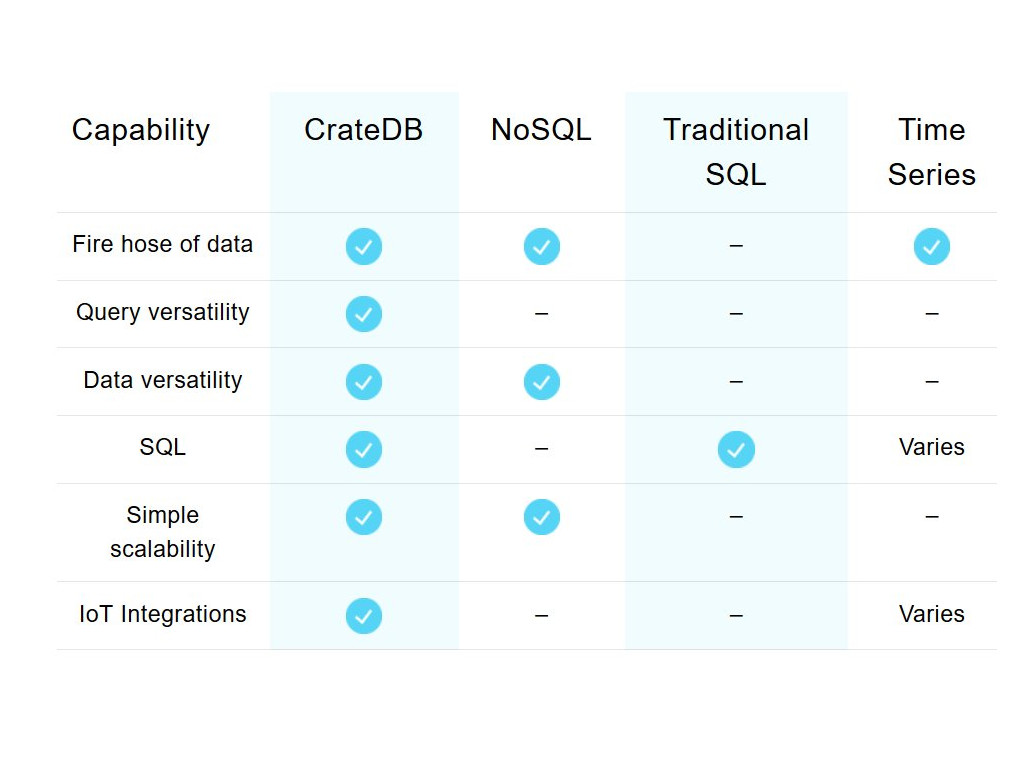 Gegenüber anderen Datenbanken beansprucht Crate für CrateDB unter anderem Vorteile bei Integrationsfähigkeiten, Skalierbarkeit und Geschwindigkeit (Bild: Crate.io)
Gegenüber anderen Datenbanken beansprucht Crate für CrateDB unter anderem Vorteile bei Integrationsfähigkeiten, Skalierbarkeit und Geschwindigkeit (Bild: Crate.io)
Neue Ansätze stammen meist aus dem Web, etwa Crate.io mit seiner CrateDB und daraus abgeleiteten Produkten wie Crate IoT Data Platform oder CrateDB Cloud. Was sie in der Praxis leisten, zeigt ein Beispiel aus der Schweißtechnik – die Firma möchte ihren Namen noch nicht veröffentlicht sehen. Der Hersteller stellt Schweißteile her, wobei innerhalb von 500 Millisekunden rund 30.000 Datenpunkte entstehen, die allesamt in Echtzeit abgespeichert und ausgewertet werden müssen.
Das Ziel der Implementierung besteht darin, mit Hilfe von Maschinenlernen schon während des Schweißvorgangs die Qualitätskontrolle der Schweißstellen mit höchster Genauigkeit durchzuführen. Dann können fehlerhafte Teile bereits in diesem Stadium aussortiert werden.
Dafür werden die aktuellen Streaming-Daten zuerst am Schweißsystem „on-the-edge“ gespeichert und dann in die Cloud weitergeleitet. Das Vor-Ort-System entscheidet in Millisekunden mit Hilfe des dort implementierten, aber aus der Cloud regelmäßig aktualisierten Machine-Learning-Modells, ob das Werkstück den Anforderungen entspricht. Fällt die Verbindung zur Cloud aus, kann die Maschine trotzdem weiterarbeiten.
Technische Finessen machen es möglich
Dass das so funktioniert, liegt an zwei besonderen Eigenschaften der CrateDB: Erstens kann sie ihre Leistung nahezu unbegrenzt und fast linear steigern. Dies deshalb, weil die einzelnen Knoten des Datenbanksystems als sogenannte Shared-Nothing-Architektur implementiert sind. Das bedeutet kurz und knapp, dass jeder Knoten genau gleich ist. Kein Knoten teilt Komponenten mit anderen Knoten. Dadurch lässt es sich einfach und elastisch skalieren und Ausfälle werden automatisch kompensiert. Die Leistung steigt einfach, indem neue Knoten hinzugefügt werden. Die erforderliche Hochgeschindigkeits-Kommunikation zwischen den Knoten erledigt das Protokoll Netty.
Auch die Storage unter dem System ist hoch skalierbar. Ihr liegt als Storage-Datenbank-Engine das Open-Source-Produkt Lucene zugrunde. Es wird auch von Elastic verwendet und bietet sogenannte Columnar Caches, einer speziellen Form, den Cache zu beschreiben. Als Hardwarebasis kann man dabei günstige Standard-Cloud-Instanzen und billige SSDs statt proprietärer Technologie verwenden, weil die die Cluster-Software für Ausfallssicherheit sorgt.
Schließlich hat Crate.io sehr intensiv an einer Technologie zur Reduktion der Datenreihen gearbeitet. Sie schreibt einen Wert jeweils nur dann in den Arbeitsspeicher, wenn er innerhalb der Datenreihen neu ist. Da die Datenreihen oft Millionen Werte erfassen, aber nur einige Tausend tatsächlich unterschiedliche, lässt sich so der Inhalt des Arbeitsspeichers merklich eindampfen. Sieht ein Anwender an einer bestimmten Stelle genauer hin, werden über einen SSD-Zugriff die im Arbeitsspeicher gehaltenen Daten durch die fehlenden Werte ergänzt.
100% SQL-konform
Das besondere Alleinstellungsmerkmal besteht darin, dass alle in Crate.io implementierten Funktionen ANSI SQL-konform sind. „Für Machine-Data Use-Cases sind alle nötigen SQL Funktionen implementiert. Im Mittelpunkt stehen für uns Funktionen, die wir für die massenweise parallele Echtzeitverarbeitung von Streaming-Daten und IoTbrauchen können. Transaktionen und ACID-Konformität streben wir dagegen gar nicht an.““, erklärt Mitgründer und CEO Christian Lutz.
Das hat für die Anwender gravierende Vorteile: „Wir ersetzen bei den Kunden in der Regel zwei oder drei Datenbanken“, sagt Lutz. So vereinigt CrateDB die Funktionen einer relationalen SQL-, einer NoSQL-Dokumenten- und einer BLOB-Store-DB in einem System. Die SQL-konforme Datenbasis der CrateDB legt sich nach unten auf alle möglichen Datenquellen und Datenbanken auf. Nach oben betrachtet, bleibt der Zugriff für bereits programmierte SQL-Applikationen offen, auch SQL-Treiber funktionieren weiter. So können die Programmierer im Unternehmen ihr aufwändig erworbenes SQL-Wissen weiter nutzen, allerdings auf einer stark erweiterten, skalierbaren Datenbasis.
Zukunftspläne: Mehr Clouds und maschinelles Lernen
CrateDB Cloud läuft auf jedem Cloud-Service. Auf MS Azure gibt es CrateDB als voll gemanagten Service, der eng mit Azures IoT-Services zusammenarbeitet. CrateDB läuft auch on-the-edge (zB an einer Maschine) und on Premises, weil, so Lutz, viele der Crate-Kunden hybride Betriebsmöglichkeiten brauchen oder ihre Daten lieber im Haus behalten. Weil Crate als typisches Open-Source- und Cloud-native-Produkt unabhängig vom Typ der Cloud ist, wird es bald voll gemanagte Varianten für AWS und Google geben. „Das schätzen vor allem große Kunden mit Multicloud-Strategien gegen Lock-In“, betont Lutz.
Zudem plant Crate DB-Funktionen für das Maschinenlernen. Denn die Lösung wird wegen der Einfachheit und Geschwindigkeit gern von Datenanalysten genutzt. Die brauchen dann ein weniger umfangreiches zusätzliches Toolset.
Crate.io, ein Unternehmen mit nunmehr 40 Mitarbeitern und Sitz in Dornbirn/Österreich und Berlin, gibt es seit 2013. Die Finanzierungsbasis ist derzeit noch Venture Capital. 2018 wurde eine weitere 11-Millionen-Runde abgeschlossen. Profitabel ist Crate noch nicht.
Nach einigen Open-Source-Varianten kam 2017 eine Enterprise-Version auf den Markt. Sie ist bisher in 1200 Clustern weltweit implementiert. Davon steht je ein Drittel in den USA, wo Crate.io inzwischen eine Niederlassung hat, in Asien und in Europa. Entwickelt wird in Europa. Zu den Kunden gehören der Verpackungsproduzent ALPLA, der Industriebeleuchtungsspezialist Zumtobel oder SAP Qualtrics. Der größte Kunde ist der Sicherheitsspezialist McAfee. Dort steht ein Produktions-Cluster mit 150 Knoten. Er speichert täglich 10 Milliarden Records und versorgt drei Millionen Enduser.
Wann die Gewinnschwelle überschritten werden soll, steht noch nicht fest. Doch die Umsatzziele sind anspruchsvoll: 2018 wurde der Umsatz mit der Enterprise-Variante verdoppelt, 2019 soll er sich gegenüber 2018 verdreifachen.
Neueste Kommentare
Noch keine Kommentare zu SQL- und Streaming-Daten hochskalierbar integrieren
Kommentar hinzufügenVielen Dank für Ihren Kommentar.
Ihr Kommentar wurde gespeichert und wartet auf Moderation.