Pharma, Healthcare, Finanzwesen und Einzelhandel gehören zu den Branchen, die sich besonders viele neue Chancen vom Einsatz analytischer Algorithmen versprechen. Typische Anwendungen sind etwa:
- In der Pharmabranche die sogenannte Drug Discovery, also die gezielte Suche nach vielversprechenden Molekülen, aus denen sich neue Medikamente entwickeln lassen.
- Im Bereich Healthcare/Genomic der Einstieg in eine personalisierte Medizin. Sie beruht auf der Korrelation statistischer Daten zu individuellen Krankheitsverläufen und Erkrankungshäufigkeiten, beispielsweise bei Krebs, Lebensgewohnheiten und der individuellen Genanalyse jedes Patienten. Ziel ist, die Therapie individuell zu gestalten bis hin zu maßgeschneiderten Medikamenten für bestimmte Patientengruppen.
- Das Finanz- und Versicherunswesen verspricht sich durch bessere Analytik beispielsweise eine häufigere Aufdeckung von Betrügereien und eine sicherere Risikobewertung etwa beim Kredit-Scoring.
- Im Einzelhandel geht es beispielsweise um die Analyse des Kundenverhaltens, um daraus Schlüsse für die Lagerhaltung, Werbeaktionen, variable Bepreisung etc. zu ziehen.
Doch ist die Anwendung von Big-Data-Analytik, KI und ML natürlich nicht auf diese Bereich beschränkt. Im Grunde kann jede Branche von neuen analytischen Fähigkeiten profitieren. Das weiß auch HPE und verstärkt sich nun gezielt durch den Aufkauf des innovativen Analytik-Plattformanbieters BlueData.
Zwar konnte die 2012 gegründete Firma Bluedata erst einige Dutzend Kunden überzeugen. Allerdings gehören die meisten in ihren Branchen (siehe oben) weltweit zu den Marktführern. Sie setzen die EPIC-Plattform testweise oder auch schon im Echtbetrieb ein – oft auf Dell EMC als Hardwarebasis, denn der Allrounder diente BlueData bislang als einer der Vertriebskanäle. Über den Kaufpreis schweigt sich HPE aus.
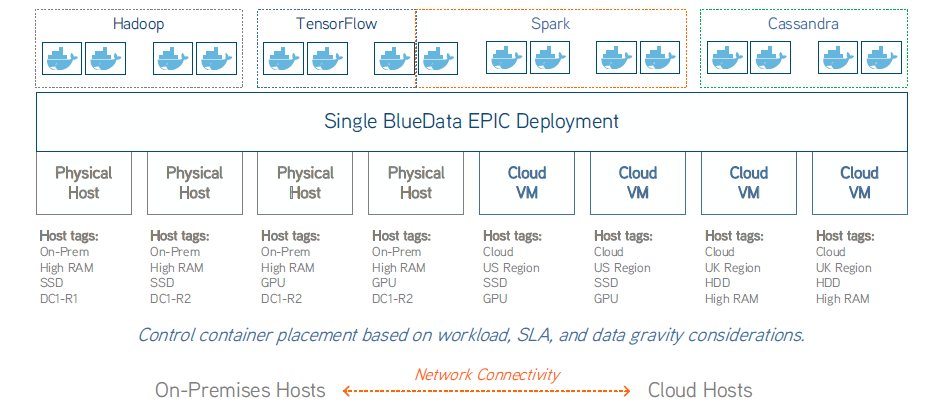
 Eine hybride EPIC-Installation (Bild: HPE).
Eine hybride EPIC-Installation (Bild: HPE).
„Wir wollten unser analytisches Portfolio verbreitern und uns hat die Technologie von EPIC überzeugt“, erklärt Patrick Osborne, Vice President Big Data und Secondary Storage bei HPE. Man habe diverse Hardwareplattformen im Programm, die gut zu EPIC passen. Außerdem passt EPIC gut zum HPEs Hybrid-Cloud-Philosophie. Mit dem Dienstleistungszweig HPE Pointnext sei umfassendes Beratungs- und Implementierungs-Know-how vorhanden, um Kunden wirksam beim Aufbau einer EPIC-Lösung zu unterstützen, sagt Osborne. Schließlich sei HPE dank der nutzungsorientierten Abrechnung von HPE Greenlake, die auch für EPIC-Systeme verfügbar ist, imstande, den Kunden am tatsächlichen Gebrauch orientierte Kostenstrukturen anzubieten.
Großkunden im Visier
Für mittlere und Kleinunternehmen ist das Angebot trotzdem eher nichts, der Einstiegspreis liegt im sechsstelligen Bereich. „Wir wenden uns an Firmen, die mehrere verteilte analytische Teams betreiben, wahrscheinlich eine hybride Cloud und verteilte Datenressourcen nutzen“, umschreibt Osborne. Auch der HPE-Channel vertreibt in Zukunft die BlueData-Lösung.
Der vor Kurzem angekündigte Aufkauf des Superrechner-Herstellers Cray steht nicht im Zusammenhang mit der Akquise, betont Osborne. Vielmehr denkt HPE, wenn es um passende Hardware für BlueData geht, beispielsweise an die Apollo-Plattform, an Memory-driven-Lösungen und an Systeme, die mit viel GPU-Power ausgerüstet sind, um Aufgaben wie beispielsweise die Bilderkennung schneller zu bewältigen.
Grundsätzlich ist EPIC aber unabhängig von Hardwareplattformen und eine reine Softwarelösung. „Kunden implementieren EPIC On-Premises gern Bare Metal. Das geht, weil die Lösung auf Docker-Containern basiert“, erklärt Osborne. Docker-Container sind nicht auf einen Hypervisor als Unterlage angewiesen. Hyperskalierende Plattformen, die ja in der Regel Hypervisoren nutzen, sind nicht die ideale Basis für eine EPIC-Implementierung, meint Osborne. Nichtsdestotrotz sei es möglich, die Softwareplattform auch dort laufen zu lassen, allerdings innerhalb einer virtuellen Maschine.
Container als Basis
Was steckt nun technisch hinter der Lösung? Wie schon gesagt, ist EPIC containerbasiert und auf die hybride Cloud ausgerichtet. Die Technologie trennt konsequent Storage von Compute. Die Grundeinheit von EPIC sind sogenannte Nodes oder vCPUs (virtuelle CPUs). Es gibt sie in drei vordimensionierten Größen. Nodes werden nach Angabe ihrer Dimensionen automatisch eingerichtet. Jede vCPU/jeder Node entspricht einem Container. Die Kosten für EPIC berechnen sich nach der Zahl der insgesamt auf dem System nutzbaren Nodes.
Kunden konfigurieren bei der Installation, wie viele vCPUs sie auf den für EPIC vorgesehenen physischen CPUs auf dem physischen Host unterbringen wollen. Direkt auf dem Host befindet sich auch der Arbeitsspeicher der vCPUs und der nutzbare Stateless-Speicher. Jedem Container können zudem bis zu 20 GByte persistenter Speicherraum außerhalb des EPIC-Systems auf Remote-Storage zugewiesen werden. Dort bleiben wichtige Containerdaten auch bei Verschieben oder Löschen des Containers im Zugriff. Das benötigen viele Applikationen.
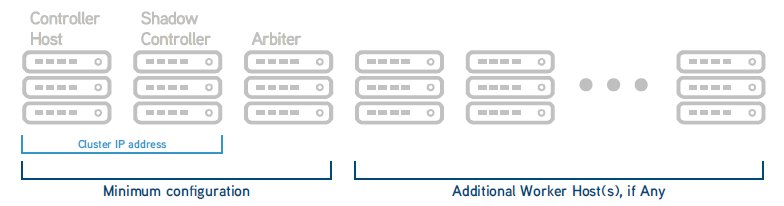
 Für Hochverfügbarkeit ist mindestens ein Cluster mit drei Controllern notwendig (Bild: HPE).
Für Hochverfügbarkeit ist mindestens ein Cluster mit drei Controllern notwendig (Bild: HPE).
Hosts können sich überall befinden und Cluster überall erzeugt werden: inhouse oder beim Cloud-Provider zum Beispiel. Nodes werden zu Clustern gebündelt, die Controller oder Worker sein und die Grenzen physischer Hosts überschreiten können. Controller steuern Worker, können aber auch selbst Worker sein. Worker erledigen die eigentliche analytische Arbeit. Hochverfügbarkeit ist ab einer Mindestzahl von drei Controllern möglich, die sich gegenseitig im Ernstfall ersetzen und auf nur einem Cluster laufen dürfen.
Analyse ohne Datenverlagerung
EPIC bietet mehrere Funktionen, die das System deutlich von anderen differenzieren. Beispielsweise DataTaps. Hier handelt es sich um mit Namen bezeichnete sichere Pfade, die zu analytisch genutzten Datenquellen führen. Die dort befindlichen Daten können analytisch genutzt werden, ohne dass man sie zu den Rechnern transportieren muss. Damit lassen sich Daten sowohl in zentralen Data Lakes als auch irgendwo im Unternehmen verteilte Datenquellen relativ unkompliziert an die Analytik anbinden. IOBoost ist ein Beschleunigungsmechanismus für die Datenein- und ausgabe in respektive aus Speichermedien.
EPIC erlaubt die Multi-Tenant-Nutzung. Nutzergruppen, Standorte, bestimmte analytische Aufgaben, Fachbereiche und so weiter lassen sich als Tenant mit spezifischen Zugriffsrechten und individuellen Zugriffswegen (DataTaps) einrichten. Mehrere Tenants können sich Hosts und Cluster teilen. Das ist wichtig für Unternehmen, die zum Beispiel Zugriffsbeschränkungen aus rechtlichen Gründen beachten müssen.
Analytische Umgebung per Point-and-Click
Besonders wichtig aus Sicht der Datenwissenschaftler, die die tägliche analytische Arbeit zu verrichten haben, sind die Tenant-spezifischen Selbstbedienungsportale, deren Einrichtung EPIC gestattet. „Heute müssen sich diese raren Spezialisten oft ihre aufgabenspezifische Infrastruktur erst zeitaufwändig zusammenbasteln“, sagt Osborne. Das birgt das Risiko, dass Analysen für den geplanten Zweck noch immer viel zu lange auf sich warten lassen.
Mit EPIC stehen im Portal die zugänglichen Komponenten zum Zusammenklicken bereit. Neben EPIC können das je nach Wunsch des Unternehmens, das die Plattform implementiert, unter anderem auch zahlreiche einschlägige Open-Source-Tools sein. Ausgewählte Komponenten verbindet EPIC automatisch zur für die spezielle Aufgabe gewünschten analytischen Umgebung.
![]()