
Man muss nicht Terminator oder andere SciFi-Referenzen bemühen: Aktuelle KI-Anwendungen haben heute schon bisweilen erhebliche Auswirkungen auf die Verbraucher und stellen daher Unternehmen vor wichtige Fragen in Sachen Governance und Ethik. Der Einsatz von KI in der Wirtschaft dient unter anderem dazu, Entscheidungen zu automatisieren, die bislang von einem Menschen getroffen wurden, also zum Beispiel von einem Sachbearbeiter oder Experten. Ein Credit-Scoring beurteilt die Kreditwürdigkeit des Bankkunden. Eine Versicherung entscheidet in ihrem automatisierten Underwriting, ob sie bereit ist, die persönlichen Risiken des Kunden zu versichern. Der Dermatologe bewertet mittels Bildanalyse das Hautkrebsrisiko des Patienten. All das ist heute schon Realität und fordert von anwendenden Unternehmen Erklärbarkeit und Transparenz.
Konsequenzen automatisierter Entscheidungen gut durchdenken
Das moralische Dilemma beginnt jedoch nicht erst mit der Entscheidung des selbstfahrenden Autos, wem es ausweicht, um einen Unfall zu verhindern. Es geht um viel trivialere, aber gleichwohl folgenschwere Entscheidungen. So wusste beispielsweise die US-Supermarktkette Target bereits über die Schwangerschaft einer Teenagerin Bescheid, noch bevor ihr Vater im Bilde war. Das geht mit dem Sammeln von Warenkorb- und Verbraucherinformationen relativ einfach: Wenn eine 19-jährige Frau im März eine Kakaobutter-Lotion, eine große Tasche, Zink- und Magnesiumpräparate und einen hellblauen Teppich kauft, kann ein Scoring-Algorithmus daraus eine recht hohe Wahrscheinlichkeit für eine Schwangerschaft mit einem Geburtsdatum Ende August ermitteln. Ist es eine gute Idee für einen Einzelhändler, dieses Wissen jetzt auszuspielen und Gutscheine für Babyartikel oder Glückwünsche zur Schwangerschaft zu versenden? Target jedenfalls hat die junge Frau im Rahmen einer Kampagne angeschrieben und einschlägige Coupons geschickt – sehr zur Überraschung des künftigen (und bis dahin unwissenden) Großvaters.
KI-Vorreiter handeln eher ethisch bewusst
Unternehmen sollten also die Konsequenzen ihrer automatisierten Entscheidungen und auch die gelernten Regeln für die Kundenansprache besser gut durchdenken. In der Tat sind sich viele Unternehmen schon bewusst, dass mangelhafte oder problematische Ergebnisse negativ auf sie zurückfallen können. Es leuchtet daher ein, dass sie Maßnahmen für einen ethischen Umgang mit KI ergreifen und die Kontrolle behalten wollen.

Das zeigt auch eine von SAS unterstützte Forbes-Studie. 70 Prozent der befragten Unternehmen weltweit, die KI bereits einsetzen, führen demnach Ethiktrainings für ihre IT-Mitarbeiter durch. 63 Prozent verfügen sogar über Ethikkommissionen, um den Umgang mit KI zu bewerten. Dabei gibt es auch einen Zusammenhang zwischen Thought Leadership und ethischem Bewusstsein: 92 Prozent der Unternehmen, die ihre KI-Implementierung als „erfolgreich“ bezeichnen, trainieren ihre Technologieexperten in ethischen Fragen – im Vergleich zu gerade mal 48 Prozent der Unternehmen, die in Sachen KI-Nutzung noch nicht so weit sind.
Wieso, weshalb, warum?
Der Kunde, Verbraucher, Bürger oder Patient hat ein eminentes Interesse zu verstehen, warum er den angefragten Kredit oder die Versicherung nicht bekommt. Oder warum ihm anhand einer datenbasierten Diagnostik ein bestimmtes medizinisches Risiko attestiert wird. Er fragt sich unter Umständen: Welche Daten wurden dazu verwendet? Habe ich überhaupt das Einverständnis zur Nutzung meiner Daten gegeben? Sind die Entscheidungen vorurteilsfrei zustande gekommen? Hier stellt sich die Frage nach der menschlichen Kontrolle.
Die relevanten Stichworte für Unternehmen sind daher Governance des Entscheidungsprozesses, Transparenz und Erklärbarkeit der Entscheidung. Betroffene müssen algorithmisch und datenbasiert getroffenen Entscheidungen vertrauen können – und zwar ohne die zugrunde liegenden Algorithmen, Prozesse oder Entscheidungsregeln verstehen zu müssen.
Doch was genau ist „Governance“? Hier kommen die „vier Säulen des Vertrauens“ ins Spiel, die Scott Shapiro von KPMG geprägt hat.
Vertrauen baut auf vier Säulen
Die vier Säulen, die Shapiro in seinem Bericht „The Automated Actuarial“ dargestellt hat, sind Qualität, Resilienz, Integrität und Effektivität. Dazu sollten Unternehmen folgende Punkte beachten:
- Datenqualität – Je weniger ein Unternehmen Daten unter Kontrolle hat, desto wichtiger ist eine klare Einschätzung, woher sie kommen, wie sie entstanden und wie gut sie sind. Das ist insbesondere für die vielen „neuen“ Datenarten aus den Bereichen Telematik und IoT, aber auch für externe Daten aus offenen Quellen wie Bilder oder Texte wichtig.
- Resilienz – Unternehmen sollten sich die Frage stellen: Wie belastbar ist eigentlich mein analytischer Gesamtprozess? Habe ich nur einen einmaligen Laborprozess? Oder ist meine Analyse auf Langfristigkeit ausgelegt? Hier gilt es, die Governance und Sicherheit entlang der gesamten analytischen Prozesskette – von den Daten bis zur automatisierten Entscheidung – sicherzustellen.
- Integrität – Entscheidend ist es, die Integrität der Datenanalyse sicherzustellen. Dazu müssen Unternehmen die Prozesse und die Wahl ihrer Methoden dokumentieren und erklären können. Passen sie zur Fragestellung? Sind sie mathematisch angemessen?
- Effektivität – Macht Analytics das, was sie soll? Sind ihre Aussagen zuverlässig? Ist sie diskriminierungsfrei?
Auditierbarkeit gefragt
Mit einer durchgängigen leistungsstarken Analytics-Plattform lassen sich diese Punkte bereits sehr gut umsetzen. Denn schon die Frage nach der Datenqualität kann sehr unterschiedlich ausfallen – je nachdem, ob sie im Zusammenhang mit Analytics und maschinellem Lernen oder im klassischem Berichtswesen gestellt wird.
Auf den Gesamtprozess bezogen sollte ein besonderer Fokus auf der Durchgängigkeit von den Daten bis zur Entscheidung liegen. Zu viele Workarounds und Werkzeugbrüche führen immer zu manuellen Schritten, Schattensystemen und damit kaum kontrollierbarer Governance. Hier spielt die Auditierbarkeit eine wesentliche Rolle: Lässt sich nachweisen, wer für wen auf Basis welcher Daten, welcher Modellversion und welchen Geschäftsregeln welche Entscheidung getroffen hat? Und durften die Daten zu diesem Zweck verwendet werden? Automatische Dokumentation, transparente Vergleichsmöglichkeiten von Algorithmen sowie Optionen zur effektiven und agilen Zusammenarbeit im Team (Stichwort DataOps) ergänzen die für die vier Säulen des Vertrauens erforderlichen Fähigkeiten.
 Dr. Andreas Becks, Head of Customer Advisory, Artificial Intelligence, SAS DACH (Bild: SAS)
Dr. Andreas Becks, Head of Customer Advisory, Artificial Intelligence, SAS DACH (Bild: SAS)
Auch Algorithmen brauchen Transparenz
Erklärbarkeit und Transparenz beziehen sich also auf den gesamten analytischen Prozess. Wie sieht es aber mit der „Blackbox“ der maschinellen Lernalgorithmen aus? Auch dort muss Transparenz durch eine analytische Plattform gewährleistet sein.
Die gute Nachricht: Ganz so undurchsichtig sind Algorithmen gar nicht. Wenn auch keine leicht verständlichen Regelwerke abzuleiten sind, so kann man doch – unabhängig vom konkreten Verfahren – untersuchen, was entscheidende Faktoren bei der algorithmischen Entscheidung sind. Das Forschungsfeld, das sich mit dieser Erklärbarkeit beschäftigt, heißt „Fairness, Accountability, and Transparency in Machine Learning“, kurz: FAT ML.
Das ideale Modell: interpretierbar & fair
Gelernte Modelle sollen nicht nur gut, sondern auch interpretierbar und fair sein. Was heißt das genau? Dafür sind folgende Fragen zu beantworten:
- Gibt es Auffälligkeiten in den Trainingsdaten, die das maschinelle Lernmodell zwangsläufig übernommen hat? Wer die Daten auswählt oder kontrolliert, bestimmt nämlich schon wesentlich die erlernbaren Zusammenhänge mit.
- Sind wichtige Zusammenhänge in den Daten ordentlich abgebildet? Kann sich jeder auf das gelernte Modell verlassen? Das Modell mag zwar, auf die Trainingsdaten angewandt, gut funktionieren – aber sind die erlernten Zusammenhänge allgemein genug, um sie auf neue Daten zu übertragen?
- Ist das Modell diskriminierungsfrei? Zum Beispiel darf eine Versicherung das Merkmal „Geschlecht“ oder dazu stark korrelierende Merkmale nicht zur Tarifierung verwenden. In Daten kann mehr oder weniger starke strukturelle und kulturelle Voreingenommenheit stecken, die dann algorithmisch gelernt und sogar verstärkt wird.
Wichtig ist, dass alle diagnostischen Verfahren zur Erklärung für die Effektivität von Algorithmen unabhängig vom konkreten maschinellen Lernalgorithmus (modell-agnostisch) sind. Partial Dependence (PD) ist ein gutes Beispiel, wie man sich solche diagnostischen Möglichkeiten vorstellen kann.
PD-Diagramm zeigt Einfluss von Merkmalen
Eine mögliche Ausgangssituation ist folgende: Für eine medizinische Diagnoseanwendung wurde ein Modell trainiert, das anhand von Patientenmerkmalen die Wahrscheinlichkeit bestimmen soll, dass ein Patient an Grippe erkrankt ist.
Ein PD-Diagramm stellt die funktionale Beziehung zwischen den einzelnen Modellinputs (also zum Beispiel Fieber, Allgemeinzustand und Hautausschlag) und den Vorhersagen des Modells dar. Ein PD-Diagramm bildet auch ab, wie die Vorhersagen des Modells von den Werten der interessierenden Eingangsgrößen abhängen – wobei gleichzeitig der Einfluss aller anderen Merkmale berücksichtig wird. So hat Fieber im Diagramm unten einen stark positiven Einfluss auf die Grippewahrscheinlichkeit, der Allgemeinzustand des Patienten einen leicht negativen, während der Hautausschlag eher indifferent ist.
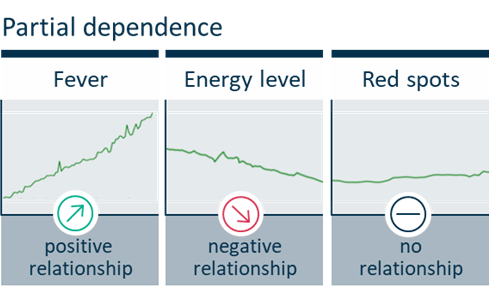
Um diese Grafiken zu erstellen, muss man für die möglichen Werte des untersuchten Inputs feststellen, welche durchschnittliche Wahrscheinlichkeit für Grippe das fragliche Modell vorhersagt, wenn man die anderen Inputs variiert. Im Beispiel: Für die Erstellung der PD-Grafik für „Fieber“ wird das jeweilige Vorhersagemodell mehrmals mit einem bestimmten Fieber-Wert (z. B.: 36,2 °C) und einer zufälligen Variation aller anderen Merkmale befüttert. Der Mittelwert der Modellvorhersagen (also die Wahrscheinlichkeit für die Diagnose „Grippe“) wird als PD-Wert für Fieber = 36,2 eingetragen. Dies wird nun für alle Fieber-Werte (36,3; 36,4; 36,5; …) wiederholt, woraus sich die grüne Linie in der Grafik ergibt. Diese zeigt uns schließlich den Einfluss von „Fieber“ bei gleichzeitiger Berücksichtigung aller anderen Merkmale.
Wie dieses Vorgehen zeigt, ist es nicht nötig, das Modell „aufzubohren“: Es ist unerheblich, wie es im Inneren strukturiert ist und wie es algorithmisch zustande kommt. So haben Unternehmen mit der Partial Dependence ein Diagnosewerkzeug, das einen speziellen Aspekt maschineller Lernalgorithmen transparent machen kann. Dieses und andere Verfahren sind bei SAS bereits an Bord.
Der Algorithmus ist keine Entschuldigung
Jeder, der mittels KI Prozesse und Entscheidungen automatisiert, muss sich mit den beschriebenen ethischen Aspekten auseinandersetzen – aus moralischen, regulatorischen und praktischen Gründen. Denn schließlich möchte kein Unternehmen, dass sich schlechte Resultate negativ aufs Image auswirken. Erklärbarkeit und Transparenz beziehen sich auf den gesamten analytischen Prozess, nicht nur auf einen Algorithmus des maschinellen Lernens, der eine Entscheidung automatisiert.
Aber auch die berühmt-berüchtigten Machine-Learning-Algorithmen sind keine für immer und ewig verschlossene Black-Box. Eine Rechtfertigung für die Folgen des KI-Einsatzes kann niemals sein: „Der Algorithmus hat mich dazu gebracht“. Erst Vertrauen und Transparenz bauen Hürden für den Einsatz von KI ab – zum Vorteil von Verbrauchern, dem Gesetzgeber und den Unternehmen, die Datenanalysen einsetzen.
Welche Auswirkungen KI auf die Gesellschaft und auf verschiedene Branchen hat, erläutert SAS auch in seiner Podcast-Serie KI Kompakt.
KI vor Ort erleben können zudem Besucher des SAS Forums 2019, das am 4./5. Juni in Bonn stattfindet.
Über den Autor:
Dr. Andreas Becks ist Head of Customer Advisory, Artificial Intelligence, SAS DACH.
Neueste Kommentare
Noch keine Kommentare zu KI in der Wirtschaft: Ohne Ethik geht es nicht
Kommentar hinzufügenVielen Dank für Ihren Kommentar.
Ihr Kommentar wurde gespeichert und wartet auf Moderation.