
Was die Befehlssätze angeht, hat AMD aufgeholt. So bieten Bulldozer-CPUs Unterstützung für den AVX-Befehlssatz, der Vektor-Operationen nunmehr mit 256 Bit Breite ausführen kann. Bisherige AMD-Prozessoren beherrschen nur 128 Bit. Sandy-Bridge-Prozessoren beherrschen ebenfalls AVX.
Noch wichtiger ist die Unterstützung der AES-NI-Befehle, die eine Verschlüsselung nach dem AES-Standard um ein Vielfaches beschleunigen können. Das ist vor allem deswegen interessant, da diese Befehle bereits von vielen Verschlüsselungsprogrammen, etwa TrueCrypt, WinZIP und Bitlocker, unterstützt werden. Intel setzt AES-NI seit der Westmere-Architektur (Nehalem-Shrink auf 32 Nanometer) ein.
In anderen Bereichen ist AMD Intel sogar einen Schritt voraus. Zwar müssen sich zwei Integer-Cores jeweils eine FPU teilen, dafür beherrschen diese Fused-Multiply-Add (FMA), was die Geschwindigkeit und Genauigkeit zahlreicher Berechnungen dramatisch erhöhen kann. Obwohl Intel FMA bereits für Sandy Bridge geplant hatte, wurde es später wieder von der Feature-Liste gestrichen und wird nunmehr erst in Haswell-CPUs Ende 2012/Anfang 2013 implementiert werden.
Hier behaupten böse Zungen, Intel habe FMA aus Sandy Bridge gestrichen, da es auch ohne FMA seine Vormachtstellung derzeit nicht gefährdet gesehen habe. Es habe sich daher ein Feature für Haswell "aufgehoben".
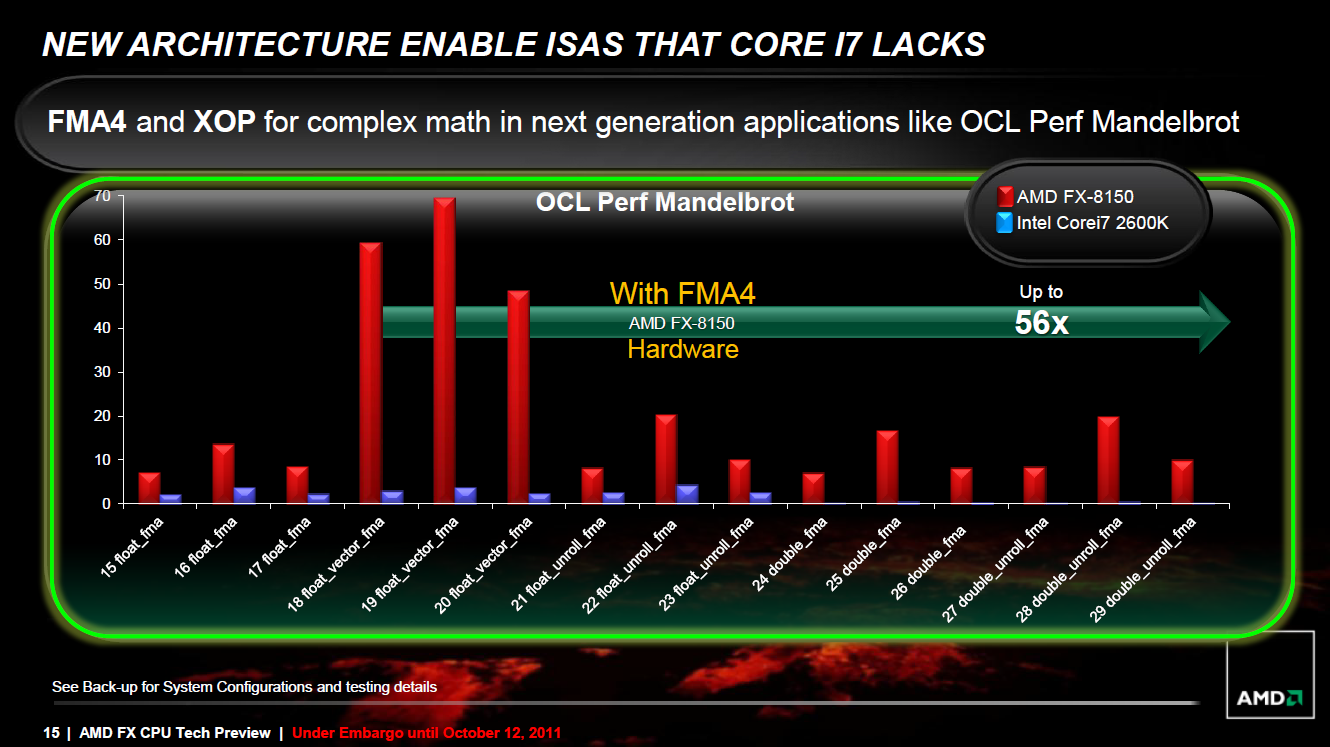
Fused-Multiply-Add kann zahlreiche Operationen dramatisch beschleunigen. In der Praxis kann man davon aber nicht profitieren (Grafik: AMD).
Allerdings benutzt AMD nicht den FMA3-Befehlssatz von Intel, sondern verwendet seine eigenen FMA4-Befehle. Damit ist die FMA-Funktionalität faktisch nutzlos für alle, die nicht ihre eigenen Programme schreiben. AMD-Spezialbefehlssätze, die bei Intel-CPUs nicht implementiert sind, werden von Softwareentwicklern traditionell ignoriert.
Ferner führt AMD den Befehlssatz XOP ein. Dabei handelt es sich um eine Abwandlung von SSE5, das an das VEX-Encoding-Schema angepasst und in XOP umbenannt wurde. Im Wesentlichen handelt es sich um Integer-SIMD-Befehle, unter anderem auch FMA, das aber bei Integer-Operationen längst nicht den Geschwindigkeitsvorteil wie bei Floating-Point-Arithmetik bringt.
Für XOP gilt dasselbe wie für FMA4: Da es ein AMD-only-Befehlssatz ist, wird man davon nicht profitieren können, wenn man Standardsoftware einsetzt.
Neueste Kommentare
Noch keine Kommentare zu FX-CPUs von AMD: Lehren sie Sandy Bridge das Fürchten?
Kommentar hinzufügenVielen Dank für Ihren Kommentar.
Ihr Kommentar wurde gespeichert und wartet auf Moderation.