
Die Apache Software Foundation hat ihre Entscheidung öffentlich gemacht, dem Framework Spark seinen Inkubationsstatus zu nehmen und es stattdessen als Projekt der höchsten Stufe zu führen. Spark ist ein In-Memory-Framework für verteiltes, clusterbasiertes Computing auf Basis eines anderen wichtigen Apache-Projekts: Hadoop.
![]()
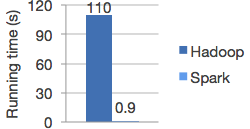
Spark hilft letztlich Hadoop, über den Betrieb mit dem MapReduce-Algorithmus im Batch-Modus auf Festplattenbasis hinauszugehen. Stattdessen wird es zu einer voll interaktiven, verteilten In-Memory-Lösung. Laut Spark-Homepage laufen Programme darauf „im Speicher bis zu 100-mal schneller als Hadoop MapReduce – und auf Disk immer noch 10-mal schneller.“ Hadoop wird so zur Echtzeit-Engine.
Damit vollzieht Apache letztlich, was die Big-Data-Community längst erwartete: Spark ist ihr wichtigster Trend, und 2014 sollte das Jahr seines Durchbruchs werden. Hervorgegangen ist das Projekt aus dem AMPLab der University of California in Berkeley, inzwischen hat es durch das Start-up Databricks kommerzielle Förderung erhalten. Als Ritterschlag für Spark kann auch gelten, dass es der führende Hadoop-Distributor Cloudera in sein CDH aufgenommen hat. CDH steht für „Cloudera Distribution including Apache Hadoop“.
Ein Apache-Inkubationsprogramm war Spark übrigens erst im Juni 2013 geworden. Zu seinen Vorteilen zählt, dass es die Hadoop-2.0-Komponente YARN und das verwandte Projekt Shark nutzen kann und eine SQL-on-Hadoop-Engine implementiert, deren Syntax kompatibel zu Apache Hive ist – aber mit den gleichen Performancevorteilen wie gegenüber MapReduce.
Die Pressemeldung der Apache Software Foundation zählt noch ein paar Vorteile auf: So ermöglichen es Sparks APIs, Anwendungen schnell in Java, Python oder Scala zu schreiben. Und weiter heißt es: „Spark ist gut für Maschinelles Lernen geeignet, für interaktive Daten-Abfragen und Stream-Processing. Es kann Daten aus HDFS, HBase, Cassandra ebenso wie aus beliebigen Hadoop-Datenquellen lesen.“
[mit Material von Andrew Brust, ZDNet.com]
Tipp: Wie gut kennen Sie sich mit Open Source aus? Überprüfen Sie Ihr Wissen – mit 15 Fragen auf silicon.de.
Neueste Kommentare
Noch keine Kommentare zu Apache befördert In-Memory-Framework Spark in den ersten Rang
Kommentar hinzufügenVielen Dank für Ihren Kommentar.
Ihr Kommentar wurde gespeichert und wartet auf Moderation.